 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecodingTrust-Agent Platform (DTap): A Controllable and Interactive Red-Teaming Platform for AI Agents
May 06, 2026AI agents are increasingly deployed across diverse domains to automate complex workflows through long-horizon and high-stakes action executions. Due to their high capability and flexibility, such agents raise significant security and safety concerns. A growing number of real-world incidents have shown that adversaries can easily manipulate agents into performing harmful actions, such as leaking API keys, deleting user data, or initiating unauthorized transactions. Evaluating agent security is inherently challenging, as agents operate in dynamic, untrusted environments involving external tools, heterogeneous data sources, and frequent user interactions. However, realistic, controllable, and reproducible environments for large-scale risk assessment remain largely underexplored. To address this gap, we introduce the DecodingTrust-Agent Platform (DTap), the first controllable and interactive red-teaming platform for AI agents, spanning 14 real-world domains and over 50 simulation environments that replicate widely used systems such as Google Workspace, Paypal, and Slack. To scale the risk assessment of agents in DTap, we further propose DTap-Red, the first autonomous red-teaming agent that systematically explores diverse injection vectors (e.g., prompt, tool, skill, environment, combinations) and autonomously discovers effective attack strategies tailored to varying malicious goals. Using DTap-Red, we curate DTap-Bench, a large-scale red-teaming dataset comprising high-quality instances across domains, each paired with a verifiable judge to automatically validate attack outcomes. Through DTap, we conduct large-scale evaluations of popular AI agents built on various backbone models, spanning security policies, risk categories, and attack strategies, revealing systematic vulnerability patterns and providing valuable insights for developing secure next-generation agents.
ShieldNet: Network-Level Guardrails against Emerging Supply-Chain Injections in Agentic Systems
Apr 06, 2026Existing research on LLM agent security mainly focuses on prompt injection and unsafe input/output behaviors. However, as agents increasingly rely on third-party tools and MCP servers, a new class of supply-chain threats has emerged, where malicious behaviors are embedded in seemingly benign tools, silently hijacking agent execution, leaking sensitive data, or triggering unauthorized actions. Despite their growing impact, there is currently no comprehensive benchmark for evaluating such threats. To bridge this gap, we introduce SC-Inject-Bench, a large-scale benchmark comprising over 10,000 malicious MCP tools grounded in a taxonomy of 25+ attack types derived from MITRE ATT&CK targeting supply-chain threats. We observe that existing MCP scanners and semantic guardrails perform poorly on this benchmark. Motivated by this finding, we propose ShieldNet, a network-level guardrail framework that detects supply-chain poisoning by observing real network interactions rather than surface-level tool traces. ShieldNet integrates a man-in-the-middle (MITM) proxy and an event extractor to identify critical network behaviors, which are then processed by a lightweight classifier for attack detection. Extensive experiments show that ShieldNet achieves strong detection performance (up to 0.995 F-1 with only 0.8% false positives) while introducing little runtime overhead, substantially outperforming existing MCP scanners and LLM-based guardrails.
Flash-Unified: A Training-Free and Task-Aware Acceleration Framework for Native Unified Models
Mar 16, 2026Native unified multimodal models, which integrate both generative and understanding capabilities, face substantial computational overhead that hinders their real-world deployment. Existing acceleration techniques typically employ a static, monolithic strategy, ignoring the fundamental divergence in computational profiles between iterative generation tasks (e.g., image generation) and single-pass understanding tasks (e.g., VQA). In this work, we present the first systematic analysis of unified models, revealing pronounced parameter specialization, where distinct neuron sets are critical for each task. This implies that, at the parameter level, unified models have implicitly internalized separate inference pathways for generation and understanding within a single architecture. Based on these insights, we introduce a training-free and task-aware acceleration framework, FlashU, that tailors optimization to each task's demands. Across both tasks, we introduce Task-Specific Network Pruning and Dynamic Layer Skipping, aiming to eliminate inter-layer and task-specific redundancy. For visual generation, we implement a time-varying control signal for the guidance scale and a temporal approximation for the diffusion head via Diffusion Head Cache. For multimodal understanding, building upon the pruned model, we introduce Dynamic Token Pruning via a V-Norm Proxy to exploit the spatial redundancy of visual inputs. Extensive experiments on Show-o2 demonstrate that FlashU achieves 1.78$\times$ to 2.01$\times$ inference acceleration across both understanding and generation tasks while maintaining SOTA performance, outperforming competing unified models and validating our task-aware acceleration paradigm. Our code is publicly available at https://github.com/Rirayh/FlashU.
Towards Principled Dataset Distillation: A Spectral Distribution Perspective
Mar 02, 2026Dataset distillation (DD) aims to compress large-scale datasets into compact synthetic counterparts for efficient model training. However, existing DD methods exhibit substantial performance degradation on long-tailed datasets. We identify two fundamental challenges: heuristic design choices for distribution discrepancy measure and uniform treatment of imbalanced classes. To address these limitations, we propose Class-Aware Spectral Distribution Matching (CSDM), which reformulates distribution alignment via the spectrum of a well-behaved kernel function. This technique maps the original samples into frequency space, resulting in the Spectral Distribution Distance (SDD). To mitigate class imbalance, we exploit the unified form of SDD to perform amplitude-phase decomposition, which adaptively prioritizes the realism in tail classes. On CIFAR-10-LT, with 10 images per class, CSDM achieves a 14.0% improvement over state-of-the-art DD methods, with only a 5.7% performance drop when the number of images in tail classes decreases from 500 to 25, demonstrating strong stability on long-tailed data.
Reliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
Grounding and Enhancing Informativeness and Utility in Dataset Distillation
Jan 29, 2026Dataset Distillation (DD) seeks to create a compact dataset from a large, real-world dataset. While recent methods often rely on heuristic approaches to balance efficiency and quality, the fundamental relationship between original and synthetic data remains underexplored. This paper revisits knowledge distillation-based dataset distillation within a solid theoretical framework. We introduce the concepts of Informativeness and Utility, capturing crucial information within a sample and essential samples in the training set, respectively. Building on these principles, we define optimal dataset distillation mathematically. We then present InfoUtil, a framework that balances informativeness and utility in synthesizing the distilled dataset. InfoUtil incorporates two key components: (1) game-theoretic informativeness maximization using Shapley Value attribution to extract key information from samples, and (2) principled utility maximization by selecting globally influential samples based on Gradient Norm. These components ensure that the distilled dataset is both informative and utility-optimized. Experiments demonstrate that our method achieves a 6.1\% performance improvement over the previous state-of-the-art approach on ImageNet-1K dataset using ResNet-18.
Token-Level LLM Collaboration via FusionRoute
Jan 08, 2026Large language models (LLMs) exhibit strengths across diverse domains. However, achieving strong performance across these domains with a single general-purpose model typically requires scaling to sizes that are prohibitively expensive to train and deploy. On the other hand, while smaller domain-specialized models are much more efficient, they struggle to generalize beyond their training distributions. To address this dilemma, we propose FusionRoute, a robust and effective token-level multi-LLM collaboration framework in which a lightweight router simultaneously (i) selects the most suitable expert at each decoding step and (ii) contributes a complementary logit that refines or corrects the selected expert's next-token distribution via logit addition. Unlike existing token-level collaboration methods that rely solely on fixed expert outputs, we provide a theoretical analysis showing that pure expert-only routing is fundamentally limited: unless strong global coverage assumptions hold, it cannot in general realize the optimal decoding policy. By augmenting expert selection with a trainable complementary generator, FusionRoute expands the effective policy class and enables recovery of optimal value functions under mild conditions. Empirically, across both Llama-3 and Gemma-2 families and diverse benchmarks spanning mathematical reasoning, code generation, and instruction following, FusionRoute outperforms both sequence- and token-level collaboration, model merging, and direct fine-tuning, while remaining competitive with domain experts on their respective tasks.
Scaling Agent Learning via Experience Synthesis
Nov 10, 2025



While reinforcement learning (RL) can empower autonomous agents by enabling self-improvement through interaction, its practical adoption remains challenging due to costly rollouts, limited task diversity, unreliable reward signals, and infrastructure complexity, all of which obstruct the collection of scalable experience data. To address these challenges, we introduce DreamGym, the first unified framework designed to synthesize diverse experiences with scalability in mind to enable effective online RL training for autonomous agents. Rather than relying on expensive real-environment rollouts, DreamGym distills environment dynamics into a reasoning-based experience model that derives consistent state transitions and feedback signals through step-by-step reasoning, enabling scalable agent rollout collection for RL. To improve the stability and quality of transitions, DreamGym leverages an experience replay buffer initialized with offline real-world data and continuously enriched with fresh interactions to actively support agent training. To improve knowledge acquisition, DreamGym adaptively generates new tasks that challenge the current agent policy, enabling more effective online curriculum learning. Experiments across diverse environments and agent backbones demonstrate that DreamGym substantially improves RL training, both in fully synthetic settings and in sim-to-real transfer scenarios. On non-RL-ready tasks like WebArena, DreamGym outperforms all baselines by over 30%. And in RL-ready but costly settings, it matches GRPO and PPO performance using only synthetic interactions. When transferring a policy trained purely on synthetic experiences to real-environment RL, DreamGym yields significant additional performance gains while requiring far fewer real-world interactions, providing a scalable warm-start strategy for general-purpose RL.
SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
May 29, 2025



Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model's social reasoning ability - the capacity to interpret social contexts, infer others' mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze
From EduVisBench to EduVisAgent: A Benchmark and Multi-Agent Framework for Pedagogical Visualization
May 22, 2025
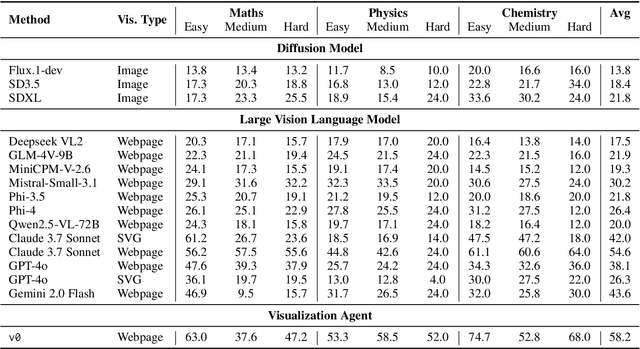
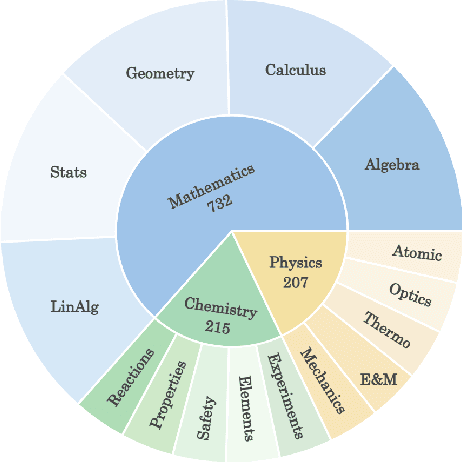
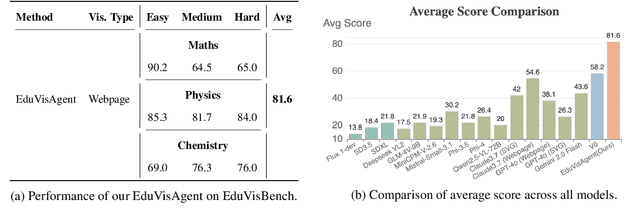
While foundation models (FMs), such as diffusion models and large vision-language models (LVLMs), have been widely applied in educational contexts, their ability to generate pedagogically effective visual explanations remains limited. Most existing approaches focus primarily on textual reasoning, overlooking the critical role of structured and interpretable visualizations in supporting conceptual understanding. To better assess the visual reasoning capabilities of FMs in educational settings, we introduce EduVisBench, a multi-domain, multi-level benchmark. EduVisBench features diverse STEM problem sets requiring visually grounded solutions, along with a fine-grained evaluation rubric informed by pedagogical theory. Our empirical analysis reveals that existing models frequently struggle with the inherent challenge of decomposing complex reasoning and translating it into visual representations aligned with human cognitive processes. To address these limitations, we propose EduVisAgent, a multi-agent collaborative framework that coordinates specialized agents for instructional planning, reasoning decomposition, metacognitive prompting, and visualization design. Experimental results show that EduVisAgent substantially outperforms all baselines, achieving a 40.2% improvement and delivering more educationally aligned visualizations. EduVisBench and EduVisAgent are available at https://github.com/aiming-lab/EduVisBench and https://github.com/aiming-lab/EduVisAgent.